Neural Language Model with Caffe
In this blog post, I will explain how you can implement a neural language model in Caffe using Bengio’s Neural Model architecture and Hinton’s Coursera Octave code. This is just a practical exercise I made to see if it was possible to model this problem in Caffe. A neural model is capable of predicting the next word given a set of previous words, the predicted word has to relate to the previous context.
A neural network is composed of hidden layers, they are a representation of our data in different dimensions, they are helpful because we can convert our data to other data representations. By working with different representations is possible to extract extra information about our data, for example we can learn to classify images with a neural net because we can represent our images with different feature representations stored in the hidden layers, in those high dimensions a picture can be represented as a single point in the high dimensional space and you can calculate distances between points to get a sense of similarity between pictures.
Word Embeddings
A high dimensional representation of a word is called a word embed, by having a different feature representation of the words we can group words by meaning similarity. That means that we can group words by their concepts, for example, fruits (apple, orange, strawberry) they all are fruits and should have a certain degree of similarity even if they are written differently)
Bengio proposed the following architecture for the word-embeddings problem:
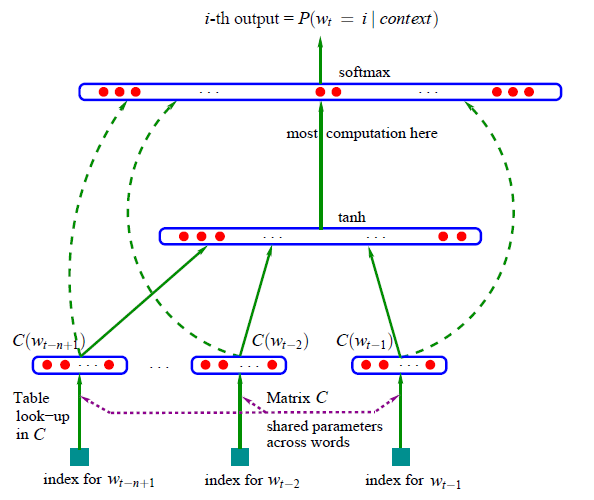
This net works by the premise that you have a static vocabulary with word codes (250 codes in the Hinton’s Coursera implementation), so for each word we are going to assign a unique code. Then a lookup operation will take place over the embedded matrix, this means that initially, this matrix will have random values but after the back-propagation learning procedure each row of this embed matrix will represent an expanded feature representation of each word in the vocabulary, this is the reason why this matrix is 250 by 50, 50 is the expanded representation of each word in 50 dimensions, this value is considered an hyperparameter and can be changed.
The net is followed then by a hidden layer with 200 neurons (in our case) in a fully connected multiplication, this layer will combine the 3 input words (in form of word embeddings) and will learn to associate them using non-linearity neurons.
The net is then followed by a softmax layer to represent the final result with 250 probabilities, the bigger probabilities are the index words of our vocabulary that will have the most in common with our input context.
Caffe Implementation
The main goal of this exercise was to create this neural net in Caffe based on the code already provided by Hinton in his Coursera Neural Network course.
1. HDF5 Data Extraction
The first thing we have to do is bulk all our training, validation and test data to an HDF5 file, this is one of the files that Caffe supports for data, the HDF5 format is recommended when we are not using image data in Caffe.
Caffe is mainly a deep learning framework focused on image processing but they state that is perfectly fine to use non-image data to make machine learning models.
Because the initial data is on a .mat format in octave, is necessary to export this to a csv file, this is Octave code required to do that:
%generate dataset from octave
[train_x, train_t, valid_x, valid_t, test_x, test_t, vocab] = load_data(372500);
csvwrite("train_x.csv",train_x')
csvwrite("train_t.csv",train_t')
csvwrite("valid_x.csv",valid_x')
csvwrite("valid_t.csv",valid_t')
csvwrite("test_x.csv",test_x')
csvwrite("test_t.csv",test_t')
This command exports our data file to a nice comma separated value format:
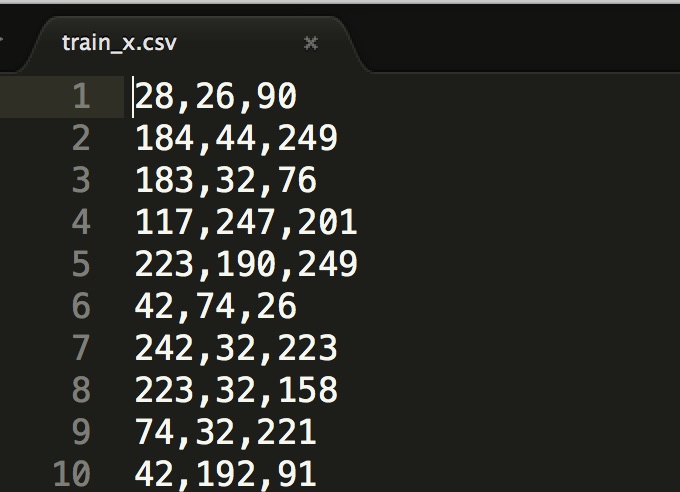
Now the first script needs to read all these csv data files and store them in an HDF5 compatible format:
import h5py, os
import numpy as np
import csv
trainXFilePath = 'csv/train_x.csv'
trainTFilePath = 'csv/train_t.csv'
testXFilePath = 'csv/test_x.csv'
testTFilePath = 'csv/test_t.csv'
#read csv training data
with open(trainXFilePath,'rb') as f:
reader = csv.reader(f)
data_as_list = list(reader)
#shape (372550, 3)
data = np.array(data_as_list).astype("int")
#read csv training data labels
with open(trainTFilePath,'rb') as f:
reader = csv.reader(f)
data_as_list = list(reader)
#shape (372550, 1)
labels = np.array(data_as_list).astype("int")
#create HDF5 file with training data and labels
f = h5py.File('hdf5/train.h5', 'w')
f.create_dataset('data', data = data)
f.create_dataset('label', data = labels)
f.close()
#read csv test data
with open(testXFilePath,'rb') as f:
reader = csv.reader(f)
data_as_list = list(reader)
data = np.array(data_as_list).astype("int")
#read csv test data labels
with open(testTFilePath,'rb') as f:
reader = csv.reader(f)
data_as_list = list(reader)
labels = np.array(data_as_list).astype("int")
#create HDF5 file with test data and labels
f = h5py.File('hdf5/test.h5', 'w')
f.create_dataset('data', data = data)
f.create_dataset('label', data = labels)
f.close()
If you follow the code you can see that this script only save all our training data into an object called “data” and all our label data into an object called “label”, this is required by Caffe to know where to read the data and the target labels. The next step is create our neural network architecture in Caffe.
2. Caffe neural net training model definition
To create a neural net in Caffe is necessary to write prototxt files, these files represent the neural net architecture and all the configurations required using a simple JSON notation.
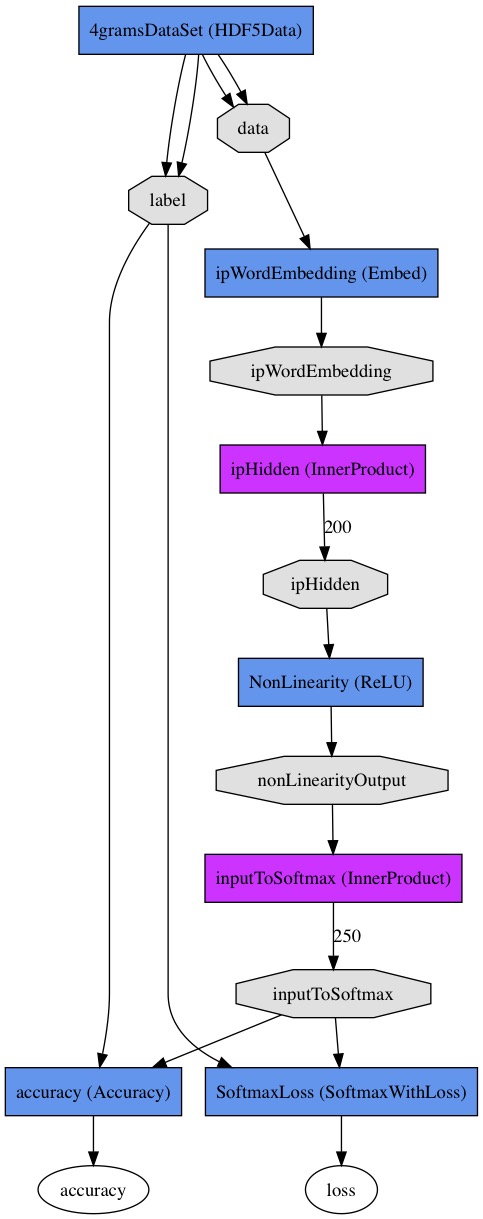
The first prototxt file we need to create will be called train_val.prototxt, in this file we will store all the architecture for our neural network, this includes all the layers and what types of neurons will have, also in this file we are going to define the data layer that will read our HDF5 files. This file is called train_val because it will define the architecture for the training phase as well as for the validation phase:
name: "LanguageNet"
layer {
name: "4gramsDataSet"
type: "HDF5Data"
top: "data"
top: "label"
hdf5_data_param {
source: "model/train.txt"
batch_size: 100
shuffle: true
}
include: { phase: TRAIN }
}
layer {
name: "4gramsDataSet"
type: "HDF5Data"
top: "data"
top: "label"
hdf5_data_param {
source: "model/test.txt"
batch_size: 100
shuffle: false
}
include: { phase: TEST }
}
layer{
name: "ipWordEmbedding"
type: "Embed"
bottom: "data"
top: "ipWordEmbedding"
embed_param {
input_dim: 251
num_output: 50
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer{
name: "ipHidden"
type: "InnerProduct"
bottom: "ipWordEmbedding"
top: "ipHidden"
inner_product_param {
num_output: 200
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "Sigmoid"
bottom: "ipHidden"
top: "reluOutput"
}
layer{
name: "inputToSoftmax"
type: "InnerProduct"
bottom: "reluOutput"
top: "inputToSoftmax"
inner_product_param {
num_output: 251
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer{
name: "SoftmaxLoss"
type: "SoftmaxWithLoss"
bottom: "inputToSoftmax"
bottom: "label"
top: "loss"
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "inputToSoftmax"
bottom: "label"
top: "accuracy"
include: { phase: TEST }
}
The code is self-explanatory although there are some important things to highlight:
The first layer of type HDF5Data reads a train.txt file and not our HDF5 file directly, this txt file has the path of the HDF5 file.
You can see that we have two HDF5Data layers, this is because for the training phase we are going to use a different dataset than the test phase, the test phase will reference the HDF5Data that corresponds to our test set.
Another thing to highlight is the embed layer, although I couldn’t find much information about how this layer works I think I managed to make it work correctly, this layer will specify the input dimensions to 250 this will be our total vocabulary and the expanded vector of 50 as specified by the output property, this means that this layer will store on a blob a matrix of 250 by 50 where each row or word will have a different feature representation of 50 dimensions, this layer will do a lookup operation (instead of a multiplication operation) for each index in our vocabulary, this functionality is required to be able to implement a word-embedding functionality correctly.
After the embed layer, we specify a hidden layer with rectified linear neurons, specifically 200 neurons, this will allow us to combine the three different word embeddings to a different feature representation dimensionality.
Finally, we do an inner product to fit the dimensions of our last layer (200) to the desired 250 dimension for the output.
Finally, we can convert this 250 vector to a vector of probabilities using a softmax layer to calculate a probability distribution, specifically, this layer is called SoftmaxWithLoss because it calculates a probability distribution and also calculates the loss with respect to our target labels.
3. Solver
Now we need to specify one more prototxt file called solver, this file will hold a lot of hyperparameters for our model, you can play with this settings to achieve better results with your model, here, for example, you can specify what optimization method you want to learn the weights, what regularization strategy you want, also you can specify the number of Epocs you need, you can also specify if you want GPU for faster training!.
# The train/test net protocol buffer definition
net: "model/train_val.prototxt"
test_iter: 1000
# Carry out testing every 500 training iterations.
test_interval: 1000
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "step"
gamma: 0.1
stepsize:20000
power: 0.75
# Display every 100 iterations
display: 1000
# The maximum number of iterations
max_iter: 100000
# snapshot intermediate results
snapshot: 50000
snapshot_prefix: "model_snapshot/snap"
# solver mode: CPU or GPU
solver_mode: CPU
4. Training the neural net
Now that the neural net model is ready we can train it using the following command:
caffe.bin train --solver=model/solver.prototxt
5. Caffe neural net deploy model definition
In Caffe you can have multiples models of a network, in this case, we want a ready to use model, this model will be used only when all our weights are trained and we have our network ready for production, this involves some small changes to the original architecture.
What we have to do is copy the train_val.prototxt to a new file called deploy.prototxt then make some small modifications:
First, we remove all the HDF5 layers, no training data is necessary because we already trained our model, then we add a new layer of type Input:
layer {
name: "data"
type: "Input"
top: "data"
input_param{
shape {
dim: 1
dim: 3
}
}
}
This new input layer will have the desired dimensions for a single input, this is 1 by 3 because the input of this network will receive just a vector of 3 dimensions specifying the first 3 words (code-words) to predict the 4th. The rest of the network will be the same except for the output layer, we are going to chop the SoftmaxWithLoss layer and replace it with a new type of layer called Softmax:
layer{
name: "softmax"
type: "Softmax"
bottom: "inputToSoftmax"
top: "prediction"
}
This makes sense because we don’t want to calculate any loss on a production phase (because we don’t have target labels) we just want to make a simple forward pass through all our learning weights to output some result, in this case, just the Softmax probabilities without any loss associated, ¿makes sense right?
6. Using the trained network
Using the trained network for production usage requires the use of the file deploy.prototxt, as I said this file is very similar to the train-val.prototxt file with just a small set of changes, the input layer is now ready to receive just one row of data and not a batch, and the last layer doesn’t calculate the loss but instead only the softmax probabilities, now we need to write some python script to use our deploy net with the trained weights:
import numpy as np
import sys
import caffe
#myWordsInput = ['they','are','well'] #23 ,
#myWordsInput = ['are','well',','] #55 she
#myWordsInput = ['how','are','you'] #55 she
#myWordsInput = ['they','had','to'] #55 she
#myWordsInput = ['there','are','times'] #55 she
#myWordsInput = ['how','are','you']
myWordsInput = ['i','did','nt']
myIndexInput = [-1,-1,-1]
vocabFile = open('csv/vocab.csv', "r")
myVocab = []
for line in vocabFile.readlines()[:]:
word = line.split('=')[1].strip()
myVocab.append(word)
# 3-gram words
myIndexInput[0] = myVocab.index(myWordsInput[0])+1
myIndexInput[1] = myVocab.index(myWordsInput[1])+1
myIndexInput[2] = myVocab.index(myWordsInput[2])+1
net = caffe.Net('model/deploy.prototxt','model_snapshot/snap_iter_100000.caffemodel',caffe.TEST)
net.blobs['data'].data[...] = myIndexInput
print "Forward Prop with values %d %d %d - %s %s %s - %s %s %s" %(myIndexInput[0],myIndexInput[1],myIndexInput[2],
myWordsInput[0],myWordsInput[1],myWordsInput[2],
myVocab.index(myWordsInput[0]),myVocab.index(myWordsInput[1]),myVocab.index(myWordsInput[2]))
out = net.forward()
print "Word prediction: %s - %s" %(myVocab[out['prediction'].argmax()-1],out['prediction'].argmax())
##top 5 predictions
top5Indexes = np.argsort(-out['prediction'][0])[:5].astype("int")
print "Top 5 predictions:"
for x in xrange(0, 5):
print " %s" %(myVocab[top5Indexes[x]-1])
print out['prediction'][0][top5Indexes[x]]
#print net.blobs
#print "EMBED"
#print net.params['ipWordEmbedding'][0].data
#print "HIDDEN"
#print net.params['ipHidden'][0].data
#print "RELU"
#print net.params['reluOutput'][0].data
#print "INPUT TO SOFTMAX"
#print net.params['inputToSoftmax'][0].data
#print "PREDICTION"
#print net.params['inputToSoftmax'][0].data
I need to explain some points: This script will read the vocab.csv file that has all the vocabulary in the form of id, value pairs for a total of 250 words, we need this just to output the predicted word in form of text and not in a code.
This line:
net = caffe.Net('model/deploy.prototxt','model_snapshot/snap_iter_100000.caffemodel',caffe.TEST)
Use the Caffe binding that is available for python, with this library we can import the caffe trained net to the python environment and use it with your developments, this line in particular imports the caffe deploy net but with the trained weights that we learned using the train-val model.
This line feeds our net with the custom input:
net.blobs['data'].data[...] = myIndexInput
Finally, we perform a single forward pass with this line, remember that this is a very fast operation because behind the scenes a bunch of matrix multiplications are happening:
out = net.forward()
Finally, the result of the fprop will give us 250 probabilities, but we only want the top 5:
##top 5 predictions
top5Indexes = np.argsort(-out['prediction'][0])[:5].astype("int")
print "Top 5 predictions:"
for x in xrange(0, 5):
print " %s" %(myVocab[top5Indexes[x]-1])
print out['prediction'][0][top5Indexes[x]]
You can find all the source code here: https://github.com/juanzdev/word-embeddings-caffe